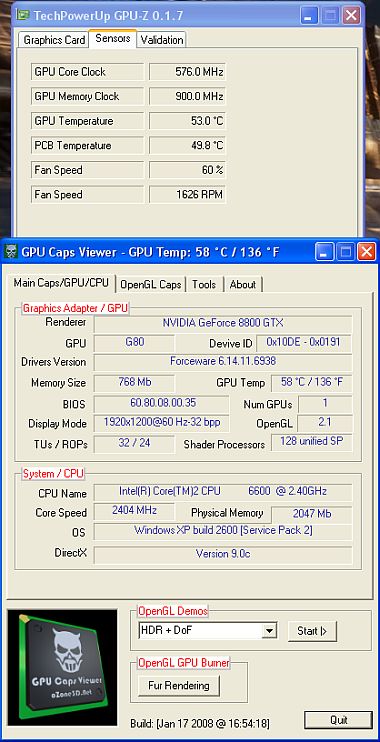
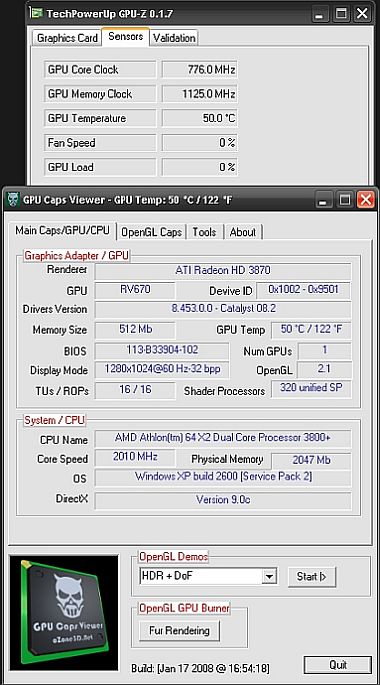
Version testée: 1.02
GLC_Player est un viewer de fichier OBJ {Alias|Wavefront}, le format standard ascii de description des modèles 3D. Ce format est très simple dans sa structure et n’impose aucune contrainte quand à l’organisation des données. C’est finalement là que réside la grande difficulté à parser ce type de fichier. Je dois dire que GLC_Player remplit correctement son role de loader de fichiers OBJ.
GLC_Player propose une navigation de camera de type Virtual Trackball ce qui est très pratique pour manipuler l’objet et le regarder sous tous les angles. GLC_Player est livré avec quelques objets mais pour le lab infame il n’est pas question de prendre des objets qui sont tous certifiés GLC_Player loadable!
Je me suis donc rendu sur cette page et j’ai téléchargé le modèle de la Ferrari F40 Ce modèle est livré au format MAX. Ca tombe bien comme ça je peux le convertir en OBJ avec l’exporter OBJ de MAX.
Pour le test j’ai aussi utilisé HyperView3D afin de comparer les chargements.
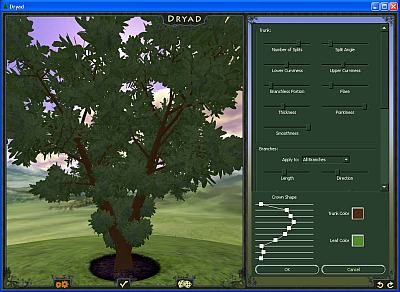
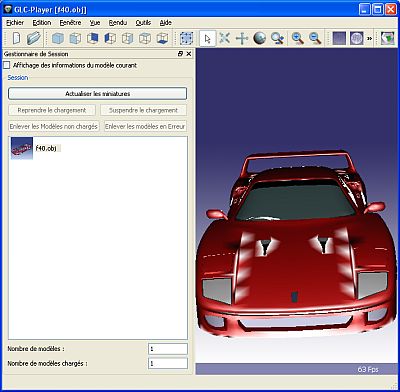
– Ferrari F40 et GLC_Player:
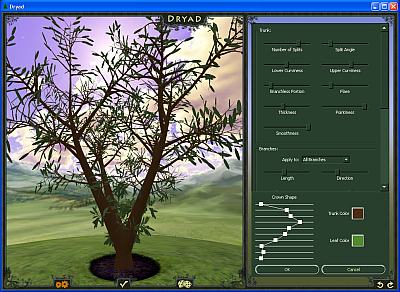
– Ferrari F40 et HyperView3D:

Les tâches blanches bizarres sur le capot viennent des normales exportées par MAX qui ne sont pas correctes à ces endroits. Ce petit détail mis à part, on voit que GLC_Player a eu un petit problème pour charger les textures (logo Ferrari sur le capot) et ne semble pas prendre en compte la transparence des matériaux (pare-brise et phares).
L’autre détail qui peut poser des problèmes pour une analyse plus fine des modèles 3D est la gestion des meshes. GLC_Player charge le fichier OBJ en un seul gros mesh alors que le modèle comporte 36 meshes distincts.
Conclusion: Pour rapidement visualiser des fichiers OBJ, je dirais que GLC_Player est parfait. Son coté multi-plateforme le rend disponible sous Windows et sous Linux. Il fait desormais partie de ma graphics toolbox à coté d’HyperView3D. Mais si vous avez besoin d’analyser un modèle 3D pour s’en servir dans une application 3d temps réel (Demoniak3D?) GLC_Player n’est pas pour le moment adapté.
Tested Version: 1.02
GLC_Player is an OBJ {Alias|Wavefront} object viewer. OBJ is the ascii standard file format to describe 3d objects. This format is very simple and do not force to follow a strict file structure. But this liberty has a price: the parsing is, in some case, quite difficult. And I must confess that GLC_Player does the job rather well.
GLC_Player offers a Virtual Trackball camera, which is very handy to handle the object and examine it under all possible angles. GLC_Player is delivered with some samples of OBJ files but for the infamous lab it’s out the question to use GLC_Player loadable certified objects!
So I jumped on that page and I downloaded the Ferrari F40 model. This model is provided in MAX format. This format is conveniant for my tests because I can convert it using MAX OB exporter.
For the test I also used HyperView3D in order to compare the way both tools load OBJ files.
– Ferrari F40 and GLC_Player:
– Ferrari F40 and HyperView3D:
The strange tasks in the hood come from the normals exported by MAX that are not correct at these places. Let’s forget this detail. We can see that GLC_Player has had a little problem to load some textures (the Ferrari logo on the hood) and does not take into account transparent materials (windshield and headlights).
The other thing that can prevent a detailed analyze of the 3d models is the way the meshes are managed. GLC_Player loads the OBJ file into a big and unique mesh even though the model has 36 distinct meshes.
Conclusion: if you need a tool to quickly view OBJ files, GLC_Player is that tool. What’s more GLC_Player is available for Windows and Linux. From now on, it lies in my graphics toolbox next to HyperView3D. But if you need a more accurate analysis of a 3d model in order to exploit it in a real time 3d application (Demoniak3D?) GLC_Player is not adapted yet.